
Visitas: 41
El sistema permite que los no especialistas utilicen modelos de aprendizaje automático para hacer predicciones para la investigación médica, las ventas y más.
Cortesía del MIT Noticias Por Rob Matheson | En las películas de Iron Man, Tony Stark usa una computadora holográfica para proyectar datos 3D en el aire, manipularlos con sus manos y encontrar soluciones a sus problemas de superhéroes. En la misma línea, los investigadores del MIT y la Brown University han desarrollado un sistema de análisis de datos interactivo que se ejecuta en pantallas táctiles y permite a todos, no solo a multimillonarios técnicos, resolver problemas del mundo real. VDS IA.
Durante años, los investigadores han estado desarrollando un sistema interactivo de ciencia de datos llamado Northstar, que se ejecuta en la nube, pero tiene una interfaz que admite cualquier dispositivo de pantalla táctil, incluidos los teléfonos inteligentes y las grandes pizarras interactivas. Los usuarios alimentan los conjuntos de datos del sistema y manipulan, combinan y extraen funciones en una interfaz fácil de usar con sus dedos o un bolígrafo digital para revelar tendencias y patrones.
En un artículo presentado en la conferencia SIGMOD de ACM, los investigadores detallaron un nuevo componente de Northstar, llamado VDS para «científico de datos virtuales», que genera instantáneamente modelos de aprendizaje automático para realizar tareas de predicción en sus conjuntos de datos. Los médicos, por ejemplo, pueden usar el sistema para ayudar a predecir qué pacientes tienen más probabilidades de tener ciertas enfermedades, mientras que los dueños de negocios pueden querer predecir las ventas. Si utiliza una pizarra interactiva, todos también pueden colaborar en tiempo real.
El objetivo es democratizar la ciencia de datos, facilitando la realización de análisis complejos de forma rápida y precisa.
«Incluso un propietario de café que no sepa de ciencia de datos debería poder predecir sus ventas en las próximas semanas para averiguar cuánto café comprar», dice el coautor y líder principal del proyecto Northstar, Tim Kraska. profesor asociado de ingeniería eléctrica y ciencias de la computación en el Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) y cofundador fundador del nuevo Sistema de Datos y AI Lab (DSAIL). «En las compañías que tienen científicos de datos, hay muchas idas y venidas entre científicos de datos y no especialistas; así que también podemos ponerlos en una sala para hacer análisis juntos «.
VDS se basa en una técnica de inteligencia artificial cada vez más popular llamada Automated Machine-Learning (AutoML), que permite a las personas con habilidades limitadas de ciencia de datos entrenar modelos de AI para hacer predicciones basadas en sus conjuntos de datos. Actualmente, la herramienta lidera la competencia de aprendizaje automático de DARPA D3M, que cada seis meses decide cuál es la mejor herramienta AutoML.
Junto a Kraska en el papel están: el primer autor Zeyuan Shang, un estudiante graduado, y Emanuel Zgraggen, un postdoctorado y colaborador principal de Northstar, ambos de EECS, CSAIL y DSAIL; Benedetto Buratti, Yeounoh Chung, Philipp Eichmann y Eli Upfal, todos de Brown; y Carsten Binnig, quien recientemente se mudó de Brown a la Universidad Técnica de Darmstadt, Alemania.

Una «pantalla ilimitada» para análisis
El nuevo trabajo se basa en años de colaboración en Northstar entre los investigadores del MIT y Brown. En el transcurso de cuatro años, los investigadores han publicado varios artículos que detallan los componentes de Northstar, incluida la interfaz interactiva, las operaciones multiplataforma, los resultados acelerados y los estudios de comportamiento de los usuarios.
Northstar comienza como una interfaz blanca en blanco. Los usuarios que cargan conjuntos de datos en el sistema, que aparecen en un cuadro de «conjuntos de datos» a la izquierda. Todas las etiquetas de datos llenarán automáticamente un cuadro de «atributos» separado a continuación. También hay una caja de «operadores» que contiene varios algoritmos, así como la nueva herramienta AutoML. Todos los datos se almacenan y analizan en la nube.

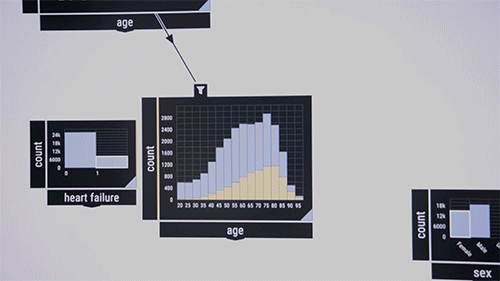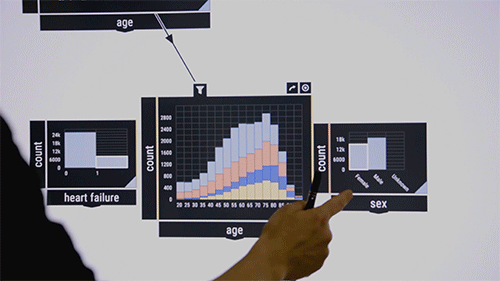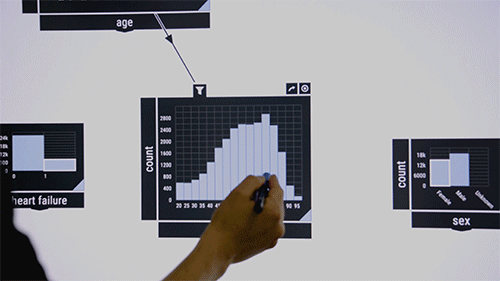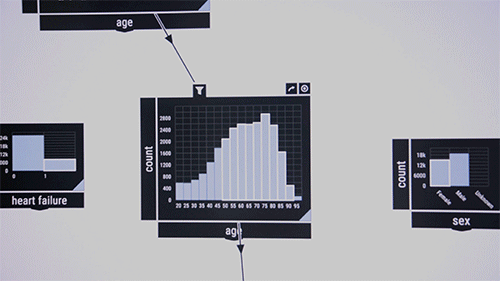
A los investigadores les gusta demostrar el sistema en un conjunto de datos públicos que contiene información sobre pacientes de unidades de cuidados intensivos. Considere a los investigadores médicos que desean examinar las co-ocurrencias de ciertas enfermedades en ciertos grupos de edad. Arrastran y sueltan en el medio de la interfaz un algoritmo de verificación de patrones, que inicialmente aparece como un cuadro en blanco. Como entrada, pasan a los recursos de la enfermedad de la caja etiquetados, por ejemplo, «sangre», «infecciosa» y «metabólica». Los porcentajes de estas enfermedades en el conjunto de datos aparecen en el cuadro. Luego arrastran la función «edad» a la interfaz, que muestra un gráfico de barras de la distribución de edad del paciente. Dibujando una línea entre los dos cuadros los enciende. Al circular los grupos de edad, el algoritmo calcula inmediatamente la co-ocurrencia de las tres enfermedades en el grupo de edad.
«Es como una gran pantalla ilimitada, en la que puedes definir cómo quieres todo», dice
Zgraggen, que es el principal inventor de la interfaz interactiva de Northstar. «Para que pueda unir cosas para crear preguntas más complejas sobre sus datos».
Acercándose a AutoML
Con VDS, los usuarios ahora también pueden realizar análisis predictivos de esos datos, adaptando los modelos a sus tareas, como predecir datos, clasificar imágenes o analizar estructuras gráficas complejas.
Usando el ejemplo de arriba, los investigadores quieren predecir qué pacientes pueden tener trastornos de la sangre en función de todas las características del conjunto de datos. Arrastran y sueltan «AutoML» de la lista de algoritmos. Primero, producirá un cuadro en blanco, pero con una pestaña de «destino», en la que descartarían la función «sangre». El sistema ubicará automáticamente las tuberías de aprendizaje automático de mejor rendimiento, presentadas como guías con porcentajes de precisión constantemente actualizados. Los usuarios pueden detener el proceso en cualquier momento, refinar la búsqueda y examinar las tasas de error, la estructura, los cálculos y otras cosas para cada modelo.
Según los investigadores, VDS es la herramienta AutoML más rápida e interactiva hasta la fecha, gracias en parte a su «mecanismo de estimación» personalizado. El mecanismo se encuentra entre la interfaz y el almacenamiento en la nube. El mecanismo de apalancamiento crea automáticamente múltiples muestras representativas de un conjunto de datos que pueden procesarse progresivamente para producir resultados de alta calidad en segundos.
«Junto con mis coautores, pasé dos años diseñando el VDS para imitar cómo piensa un científico de datos», dice Shang, que significa identificar instantáneamente qué pasos y modelos de preprocesamiento deben o no deben realizarse en ciertas tareas, en función de Reglas codificadas. Primero seleccione de una lista grande de estas posibles líneas de aprendizaje automático y ejecute simulaciones en el conjunto de muestras. Al hacerlo, recuerda los resultados y refina su selección. Después de entregar resultados aproximados rápidos, el sistema refina los resultados en el back-end. Pero los números finales suelen estar muy cerca de la primera aproximación.
«Para usar un predictor, no tiene que esperar cuatro horas para recuperar sus primeros resultados. Ya desea ver lo que está sucediendo y, si detecta un error, puede solucionarlo de inmediato. Esto normalmente no es posible en ningún otro sistema «, dice Kraska. El estudio anterior de los investigadores, de hecho, «muestra que en el momento en que pospones los resultados de los usuarios, comienzan a perder su participación en el sistema».
Los investigadores evaluaron la herramienta en 300 conjuntos de datos del mundo real. En comparación con otros sistemas AutoML de próxima generación, los enfoques VDS fueron tan precisos pero se generaron en segundos, lo cual es mucho más rápido que otras herramientas que operan en minutos u horas.
Luego, los investigadores buscan agregar una función que alerta a los usuarios sobre posibles sesgos o errores en los datos. Por ejemplo, para proteger la privacidad del paciente, los investigadores a veces etiquetan conjuntos de datos médicos con pacientes con 0 (si no conocen la edad) y 200 (si el paciente tiene más de 95 años). Pero los principiantes pueden no reconocer tales errores, lo que podría eliminar completamente sus análisis.
«Si eres un usuario nuevo, puedes obtener resultados y pensar que son geniales», dice Kraska. «Pero podemos advertir a las personas que, de hecho, puede haber algunos valores discrepantes en el conjunto de datos que pueden indicar un problema».

Dejar una contestacion